nvm介紹
Node Version Manager (NVM) 是用來管理Node.js版本,可以同時安裝多個不同版本,因應不同專案環境去快速做切換
安裝方式
Windows
Windows環境下到nvm-windows Releases提供最新版本的安裝檔案,Assets處下載nvm-setup的檔案
執行exe檔案進行安裝流程
安裝完成後在cmd輸入nvm測試是否安裝成功 若成功會跳出nvm version
1 | nvm --version |
Node Version Manager (NVM) 是用來管理Node.js版本,可以同時安裝多個不同版本,因應不同專案環境去快速做切換
Windows環境下到nvm-windows Releases提供最新版本的安裝檔案,Assets處下載nvm-setup的檔案
執行exe檔案進行安裝流程
安裝完成後在cmd輸入nvm測試是否安裝成功 若成功會跳出nvm version
1 | nvm --version |
過去對 blog 的留言板功能用過 Disqus,用了之後會在留言處自動插入廣告
看到 utterances 使用 github issue 當作留言板的儲存位置覺得滿酷的,就來研究一下
到 GitHub 創建一個公開的儲存庫
到utterances app並在 GitHub 上啟用,選擇剛剛新增的儲存庫
到utterances官網進行參數設定,下拉到 Repository 處 repo:填入留言板綁定的專案名,圖片中有提到要注意的事項:專案要是公開的、有授權utterances app

設定 issue 標題取名方式,有以下幾種:
設定 issue 標記名稱(選填)
設定留言板主題配色
建立好的儲存庫透過 hexo 建置好一個 blog,並修改成 Next 樣式
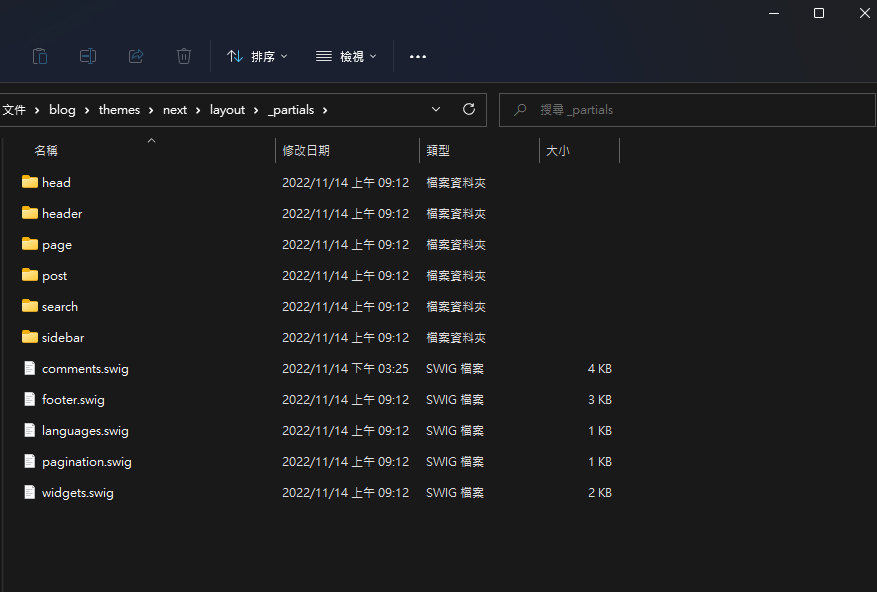
複製自動產生的程式碼到 themes\next\layout_partials\comments.swig
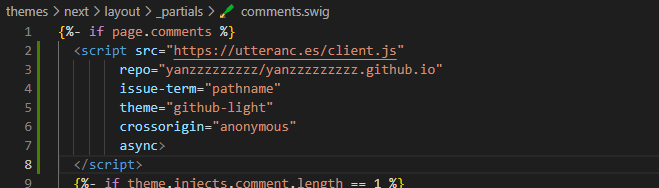
在 theme\next_config.yml 最下面加入啟用 utterances 語法
1 | utterances: enable: true; |
官方教學跟各種線上教學都非常多也非常詳細,但我竟然 Debug 了一小時…
在做完以上流程後出現了留言功能,但在按下登入時…

網址觀察後發現是config的url + 當下文章的path
1 | http://example.com/2022/11/14/post/?utterances=2ea222cae0003a078fc8aa047N244Fhi3TkHCsP8Hl%2F9pfC29qC7R2n1HjJm3apPbnWhu6UcHQz8c0ueHm%2FWRMWuA7WS2%2FFH1ykmbf2OxNakOqPEWQR4krMr7rU6vwG7gyd0lpDR1hf4r%2FuNirY%3D |
因此將_config.yml url,改成設定的 repo 位置就可以了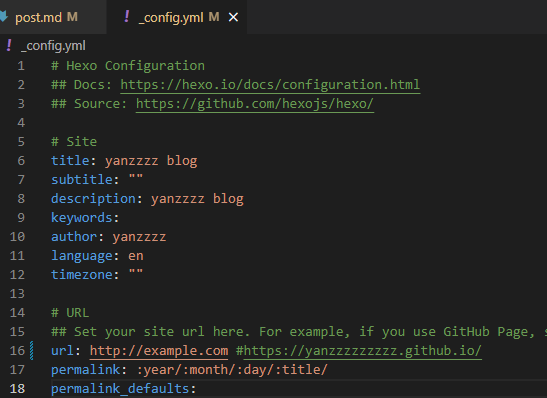
光流是描述視覺運動的一個方法,透過具有時間序列的影像來得到影像中不同物件的運動速度與他們的運動角,有了運動光流資訊可以用來:
舉例來說一個影片由多個連續影像組成,我們追蹤不同影像同一點P,第t個frame時位置是P(x1, y1),在t+1時位置是P(x2, y2),透過這兩點座標就可以算出運動方向與運動速度

要算出這兩點光流的前提:
移動前後兩點的亮度應該是相等的

$ I(x, y, t) = I(x + u, y + v, t+1) $

在以上條件約束的前提下,亮度恆定與微小移動下
$ I(x, y, t) = I(x + u{\delta}t, y + v{\delta}t, {\delta}t) $
對等號右邊的式子進行泰勒展開式,保留一階項
$ I(x + u, y + v, t+1) \approx I(x,y,t)+I_x∙u+I_y∙v+I_t$
假設亮度不變,下個時間同個點的亮度相等
$ I_x∙u+I_y∙v+I_t \approx 0$
$ \nabla I∙[u,v]^T + I_t = 0 $
不能透過等式 $ \nabla I∙[u,v]^T + I_t = 0 $ 解出u,v,因為只有一個等式內含有兩個未知數u,v
用來預估車流移動方向的光流法:

現在最紅的AI,也就是以深度學習,資料驅動的模型來預測、評估得到結果
為了加強對於Machine learning的廣度與深度理解,在網路上看到一個Machine learning roadmap的圖,整理得滿不錯的
Roadmap:https://whimsical.com/machine-learning-roadmap-2021-MJ9c7zUafrUKFzheRJ8jwy
Roadmap提供所有想了解機器學習的人一個整理:
他其實已經很完整,廣度及深度都已經有了,剩下的是如何從整理好的關鍵字向下研究,提高深度
例如:github上的Deep-Learning-Papers-Reading-Roadmap,它提供了學習方面的整理,有序的讓你了解到Deep learning這方面的經典模型
如果從Road map了解後對某一部份更有興趣,可以學習並尋找更多資源,然後填上認為缺少的重要訊息
接下來我想從這個Roadmap上的關鍵字進行相關的整理,再次對機器學習/深度學習上做一個複習
論文連結:Fast Branch Convolutional Neural Network for Traffic Sign Recognition
論文使用深度學習架構來辨識交通號誌,辨識交通號誌是高級駕駛輔助系統的重要部分,像是方向號誌、限速號誌、各種警示號誌等等
論文遇到的挑戰是影像成像受到室外環境的複雜變化,如失真、惡劣天氣、過度曝光、曝光不足、運動模糊、褪色、複雜背景,造成辨識方法更具挑戰性
使用傳統的電腦視覺辨識方法在這多變的影像是很難以用單一個演算法流程得到穩健的辨識模型,因此使用CNN架構的模型來辨識
CNN往往需要大量的參數處理來得到結果,因此要達到即時辨識模型會有一定的難度,但目前也有許多即時的CNN模型,例如:YOLO
受生物機制的啟發,論文提出一個新的架構Branch Convolution Neural Network (BCNN),在神經系統中,簡單、反射動作會在神經系統較低層次做快速反應,困難的動作會在高階的神經系統處裡後做反應,例如:在容易區分的交通號誌圖片,人眼只看一部份也可以很快的辨識出來,套用在CNN上,沒有必要通過所有CNN參數才得到結果
CNN模型在輸入交通標誌資料有以下特性
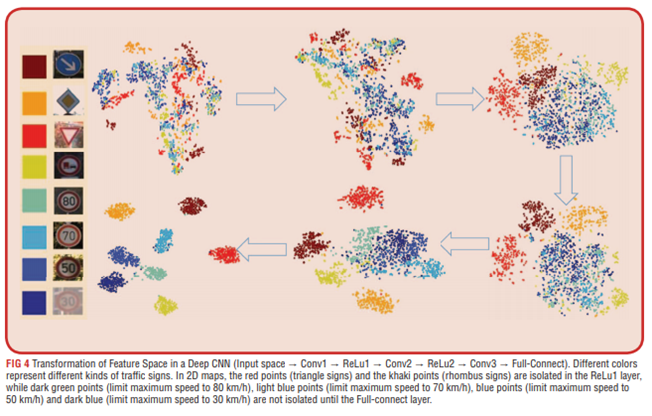
CNN和BCNN的差別在於,BCNN會在層與層之間分支輸出結果,如圖所示,傳統的CNN模型會在最後Softmax層輸出結果,BCNN模型會在其中一個分支進行預測,因此可以提高模型的預測時間

所有的樣本都不需要經過整個CNN模型,參考前段介紹的生物學機制,簡單好辨識的影像在前期的layer預測,較難的影像在後期的layer輸出結果
BCNN model訓練流程:
分支分類器是用來快速、高精度的輸出結果,因此false negatives是允許的,但false positives是不行的
因此簡單來說分支分類器:
由於分支分類器是使用線性分類器,使用k-folder來訓線性分類器,但分類器分的精度太高,也是沒有意義的,例如:分類結果為一個空間只有一個正樣本,他的precision是1,但recall可能非常低,因此設定precision與recall的threshold是必要的
再來就是要考慮到底要在哪幾層加入分類器,當遇到難以識別的樣本,並不會在分支分類器輸出結果,因此需要謹慎考慮分類器的插入位置與數量
迭帶搜索最佳組合流程
其中$ T_{save} $表示的是節省的時間,因此要最大化目標函數
$ T_{save} $公式:
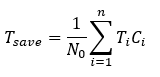
參數定義

$ l_i, i=0,1,2…n+1, 表示CNN第i層, l_{n+1}是輸出的layer, l_0是輸入的layer $
$ T_{l_i}是第l_i層到l_{n+1}層花費的時間 $
$ C_i 表示第i層的branch classifier是否存在,當C_i=1,存在分支分類器,C_i=0則不存在 $
$ t_i 是C_i分類器對sample處理所花費的時間 $
$ S_i 是到C_i層還沒被分類的sample $
$ C_iS_i第i層分離出來的sample數 $
$ S_i^*是第i層還沒被分離出來的sample $
$ N_i^* 是 S_i^* 的數量 $
$ N_0是所有sample$
$ N_i是到第i層的sample數量 $
$ N_i^- 是第i層還沒被分類出來的數量 $
$ T_i 是第i層的sample數量 - 第i層前節省的時間 - 未分類數量*分類器平均時間 $
$ T_{save}是平均節省的時間 $

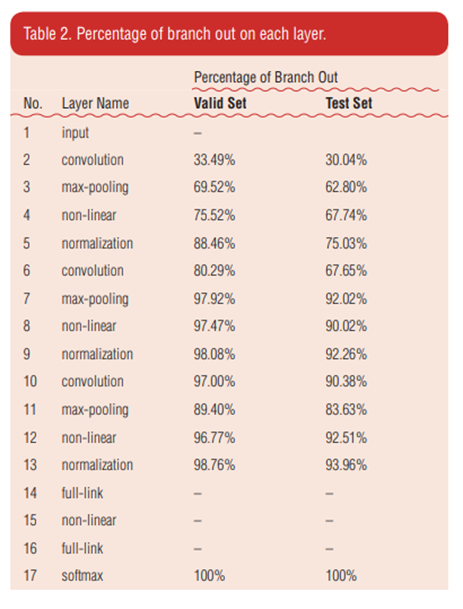
圖表顯示每個分支分類器分離輸入影像的百分比,將近30%輸入影像從第二層分離出來,並且將近75%從第五層分離出來。
這意味著可以提前分離出大量sample。 所以,BCNN可以節省大量無意義的計算。
儘管設置了一個高精度閾值,但不可避免地還是會有sample被錯誤分類。
就像訓練的準確性和測試準確性之間的關係一樣,原始模型和BCNN準確性之間存在較大差異。
圖片內的(a)顯示是在第5層之前隨機分離出的符號,(b)是在最後12層中隨機分離出的符號。(b)中的符號顯然更扭曲,模糊和更暗。與(a)相比,(b)中的樣本難以區分和識別。
我們將在前一層中分離出來的樣本命名為簡單樣本。更難識別的交通標誌被識別出來,後來被識別出來。
它與生物學機制一致,即簡單的動作被整合到一個較短的感知,而復雜的序列則以更長的周期被整合。
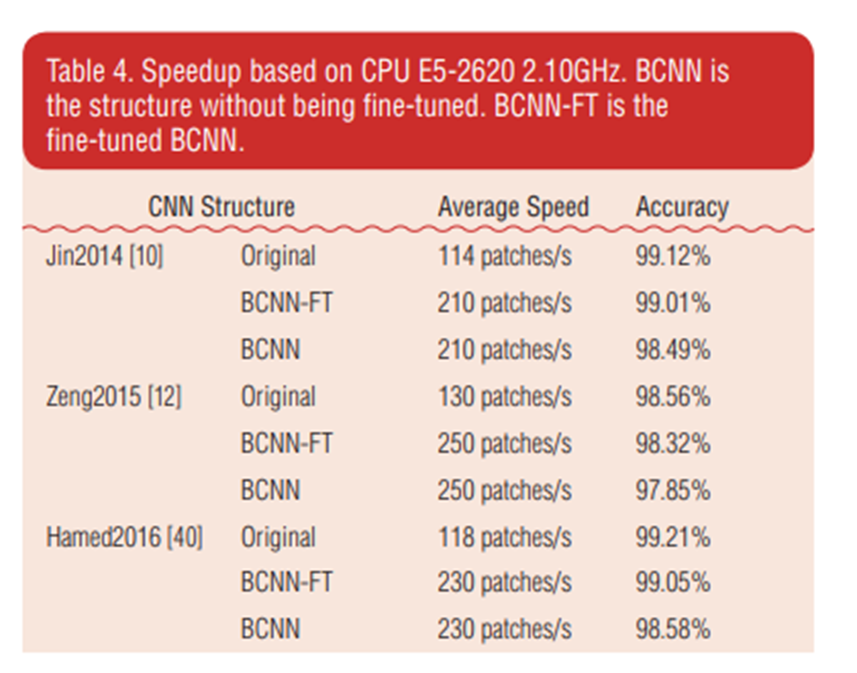
可以看到在準確度與原始CNN差異不大情況下,速度提升了約兩倍
在BCNN-FT,Fine tuned微調的情況下,更接近原始CNN的準確率
物件檢測是視覺中常見的任務之一,在影像中透過各種演算法來偵測到物件位置,常見的檢測如找到物件位置,並用矩形框標註,更精細一點的可以分割出物件的輪廓,其中會遇到的挑戰:
因此為了測試演算法在不同類別上都能有強大的適應性,網路上有多種不同的大型影像資料庫,並附上物件的位置、類別資訊來進行驗證,以下介紹常見的影像資料庫PASCAL VOC、ImageNet、COCO
網頁上有每一年的資料更動,起初只有四個類別,1578張影像,比賽方式為檢測與分類
經過多年的資料量擴增,變為20個類別,含有11530張影像,並且有27450個ROI影像與6929個更精細的分割影像區域,並加入影像分割挑戰
競賽從2005年到2012年停止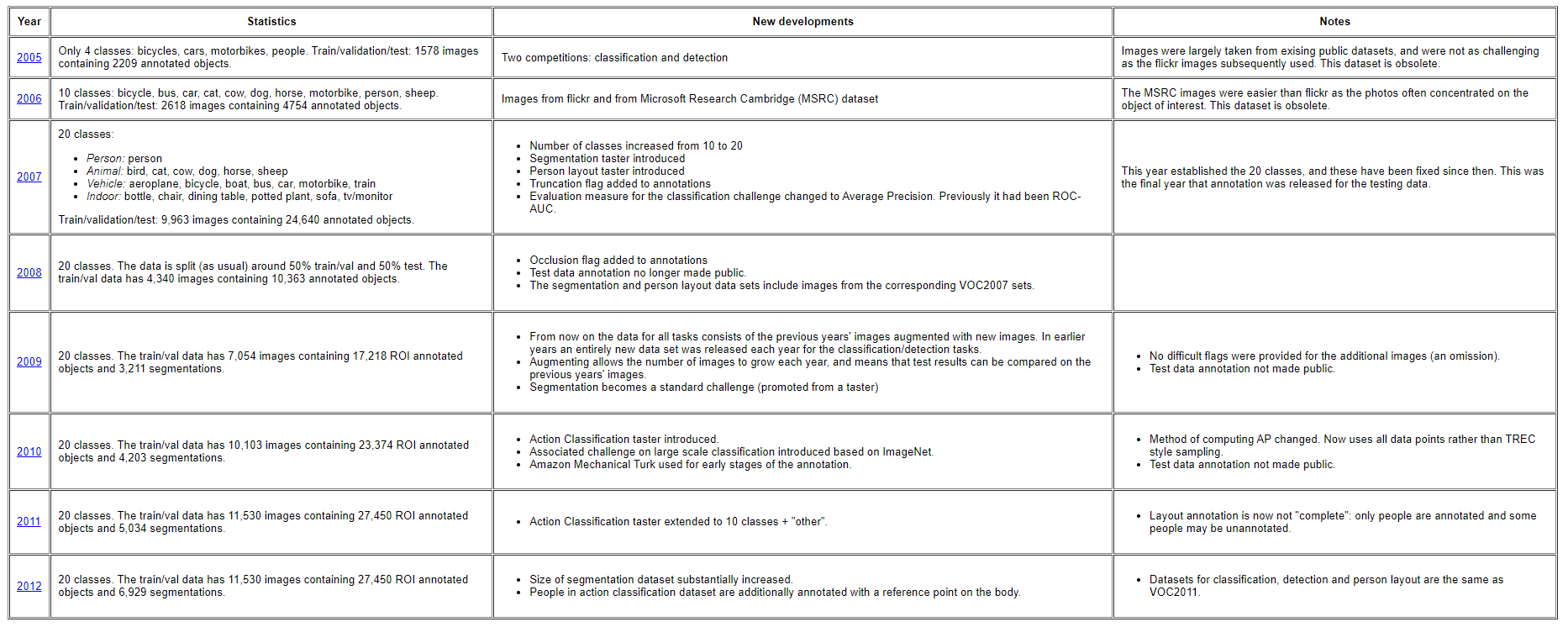
PASCAL Visual Object Classes Homepage
paperswithcode PASCAL VOC Semantic Segmentation
ImageNet是一個提供所有研究人員進行大規模影像辨識模型的資料庫,資料庫內以手動標註了1400多萬張影像,並包含2萬多個類別,實際進行挑戰時會整理出1000類來進行比賽
其中ImageNet的標記類別是根據WordNet的結構,WordNet可以想成是一個辭典,這個辭典把相近意義的同義詞連結再一起,成為一個網路架構
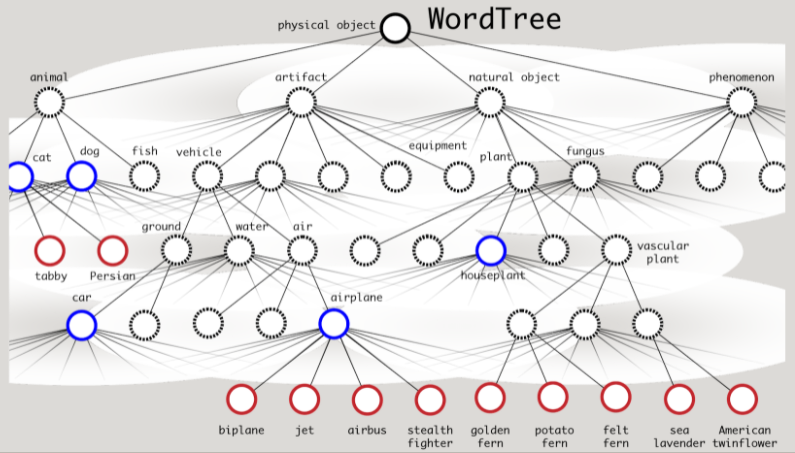 引用YOLO9000的圖來說明,WordNet結構是一個樹狀結構,一個節點下有多個子節點,例如飛機節點,下面有雙翼飛機、噴射機、空中巴士、隱形戰鬥機,因此在ImageNet中看到這些標記類別,都可以視為飛機類別
引用YOLO9000的圖來說明,WordNet結構是一個樹狀結構,一個節點下有多個子節點,例如飛機節點,下面有雙翼飛機、噴射機、空中巴士、隱形戰鬥機,因此在ImageNet中看到這些標記類別,都可以視為飛機類別
Download ImageNet Data on Kaggle

paperswithcode ImageNet object detection
的數據可以看到歷年來ImageNet影像分類比賽準確率的模型
COCO dataset也是一個大型物件檢測、影像分割的一個資料集,他的特點參考官網介紹:
paperswithcode coco object detection
在物件檢測中,常使用precision, recall來評估模型
講到precision, recall前先介紹混淆矩陣與真陽TP、真陰TN、偽陽FP、偽陰FN
precision, recall公式:

precision公式意義:預測的為正樣本的結果中,預測正確的比率,稱為準確率
recll公式意義:取出所有正樣本結果,實際預測多少正樣本的比例,稱為召回率
以垃圾郵件分類器來舉例precision, recall數值高低的關係
垃圾郵件資料為正樣本, 不是垃圾郵件的資料為負樣本
分類器的precision高, recall高, 代表這模型非常棒, 具有濾除垃圾郵件的能力
precision高, recall低, 代表這模型預估是垃圾郵件的正確率很高, 但實際抓到垃圾郵件的數量少, 是謹慎的模型
precision低, recall高, 代表這模型垃圾郵件幾乎都有抓到, 但誤判率高, 是寬鬆的模型
precision低, recall低, 這模型沒用了
好的模型是具有高準確率,又有高召回率,因此可以使用我兩個都要的F-score指標
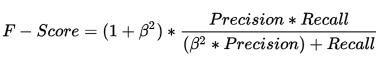
$\beta$ 值用來控制precision與recall之間的權重, $\beta$ 值越高,precision的結果就比較重要
論文閱讀:Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories
作者Svetlana Lazebnik, Cordelia Schmid, Jean Ponce
本論文提出一個方法來進行場景辨識
將影像劃分成越來越細的子區域
並計算每個子區域內的局部特徵直方圖
可以分成兩種特徵

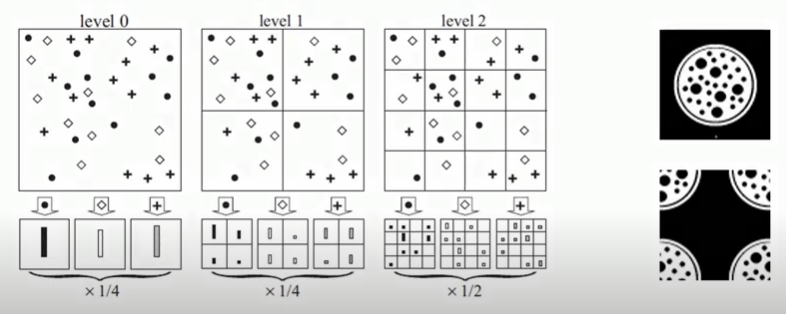
右上圓圓像細胞的是輸入的影像
左邊三個level是本篇文章提出的一個分割方法
隨著level提高, 分割的數量逐漸增加, 概念就跟金字塔一樣
從level 0來看,將輸入的影像經過特徵萃取
每個點代表不同的Bag Of Visual Words
計算每個特徵個別總和並用直方圖表示,如level 0下的長條形

而在level 0最終可以得到一個1*3的向量來表達這張影像
到level 1部分,將影像切成4等份
因此下面的直方圖也會有四份
順序是對應著圖中的紅色數字進行量化
level 1就可以得到1*12的向量
level 2就可以得到1*48
再拿這些向量去對其他影像進行比對
在原論文3.1節寫到如何匹配
定義X,Y是兩個取出d維特徵向量的集合
$ \ell $ 是金字塔的等級,第l等級會有 $ 2^{\ell} $ 的網格數
每個網格會有$D= 2^{\ell d} $的維度向量
定義 $ H^{\ell}_X $, $ H^{\ell}_Y $ 是X,Y對應的histogram
匹配公式:

用下面的例子來簡單舉例:

可以看到在level 0 兩邊都至有8個點
level 1 左上最少 1, 右上最少 1, 左下最少 2, 右下最少 2 點以此類推
其實公式的精神就是再說,取出X,Y每個格子的的最小數量作為交集數量
而level與交集數量的關係:
level 0 是一個全局的角度,因此早期的匹配到很多點數量不代表真的相似,因為level 0並沒有任何空間的訊息,隨著level越來越高,分割越細,所match到的點數量越能表示他們的相似程度
因此每層的權重公式:
level0 權重 = $ \frac{1}{2^L} $
其他 = $ \frac{1}{2^{L-\ell+1}} $
由於金字塔的計算方式,會有點數重複計算到的問題,為了消去這個重複性
計算第 0 層到第 $ L-1 $ 的實際點數公式為:
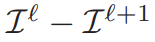
把上述兩個公式合在一起得到pyramid match kernel:

論文將所有特徵向量量化成M個離散形式,最終公式為:
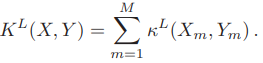
使用SVM訓練模型來進行多個類別分類
Spatial Pyramid Matching Scene Recognition
Spatial Pyramid Matching presented by Lubomir Bourdev
C 7.2 | Spatial Pyramid Matching | SPM | CNN | Object Detection | Machine learning | EvODN
Visual bag of words視覺詞袋模型概念:將影像取出具有特徵的地方,存在待比對區域中,新影像進來時,逐一比對影像符合詞袋中哪個的特徵比較多,就跟詞袋中的影像越相似,常用來進行影像分類或影像檢索
新影像進來時,逐一比對影像符合詞袋中哪個的特徵比較多,就跟詞袋中的影像越相似,就可以將它分為詞袋中相近的那一類
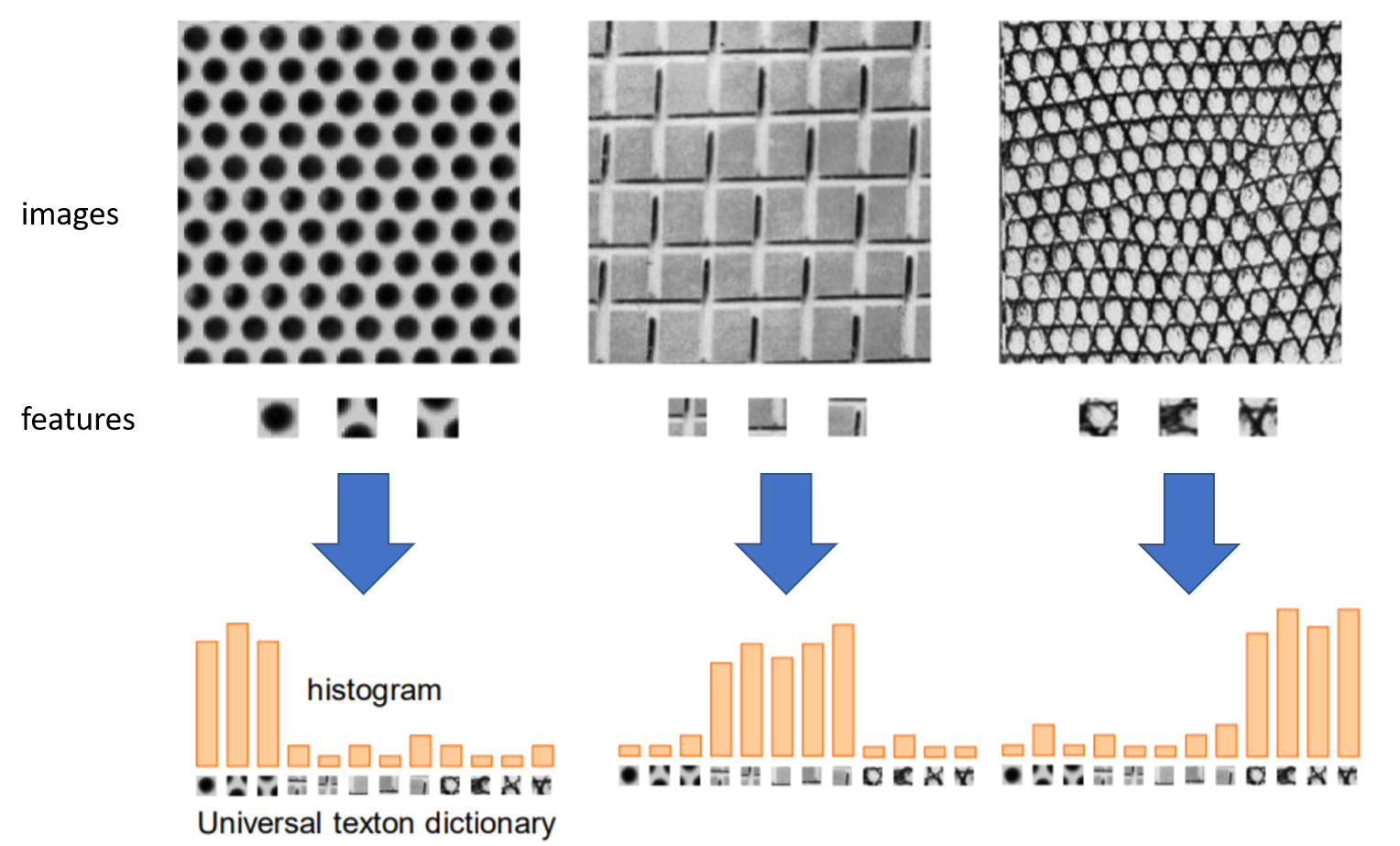 上圖可以看到在影像中,先取出各自的特徵,將這些特徵統一對各自影像進行評分,可以看到從原影像取出的特徵分數是比較高的
上圖可以看到在影像中,先取出各自的特徵,將這些特徵統一對各自影像進行評分,可以看到從原影像取出的特徵分數是比較高的
特徵取得方式參考文本分析方法,文本分析中由單詞出現的頻率來去做分析,圖片則是由紋理特徵出現的頻率高低作分析
而課程中提到的方法的關鍵字:
假設資料集中有狗、貓、飛機、山丘
透過剛剛的特徵提取可能會找到狗尾巴、貓耳朵、飛機的機翼、山丘上的樹等特徵
這些特徵之間會因為他們影像所呈現的方式而有相似性
我們在透過一個歸納個方法來將一群相似的特徵聚集再一起
使用k-means分群法來將相似的特徵組成一群
再取出各群之間的群心代表該群的特徵向量
codebook概念:codebook是由一群codevector或codeword組合而成,最終目標是以這些編碼向量來代表空間中全部的資料向量(ex:k means各群心的結果)
簡單來說,一組大資料用codebook內的codeword組合而成,用來降維,降低資料量
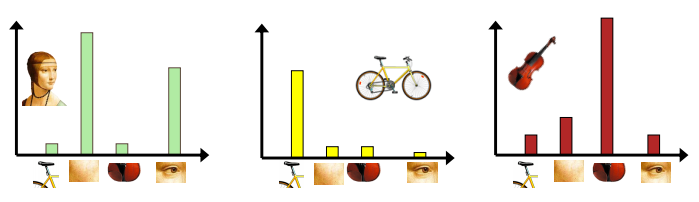
上圖可以看到當輸入的影像進來時,可以透過各個不同的特徵來評估他屬於哪一類,達到影像分類的效果
作者使用11個類別,每類影像數不同
輸入影像後,取SIFT descriptor
再透過k-means分群法將特徵分成1000群
訓練一個SVM mdoel,輸入資料為k-means的群心與對應的類別標籤
輸入測試資料進行分類評估model準確度
參考cs231n Image Classification
參考 paper:Analyzing Appearance and Contour Based Methods for Object Categorization
建造一個架構,用來辨識影像,輸入影像後會輸出對應類別結果


訓練階段重點:
dataset:ETH-80 dataset

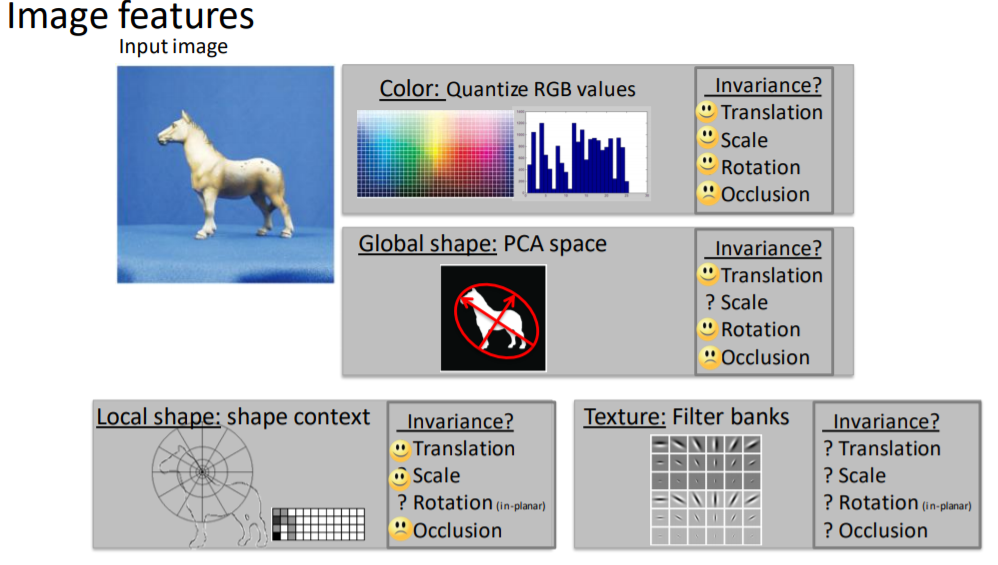
提到了幾個特徵提取方法
可使用KNN classifier


KNN的概念是由nearest neighbor algorithm衍伸出來,NN是透過一群已經存在的訓練資料與標籤當作基底,來對測試資料進行比對,輸出與訓練資料相似度高的類別當作結果
而KNN與NN不同的則是取出前K個相近的資料做參考,來決定最終輸出的類別結果
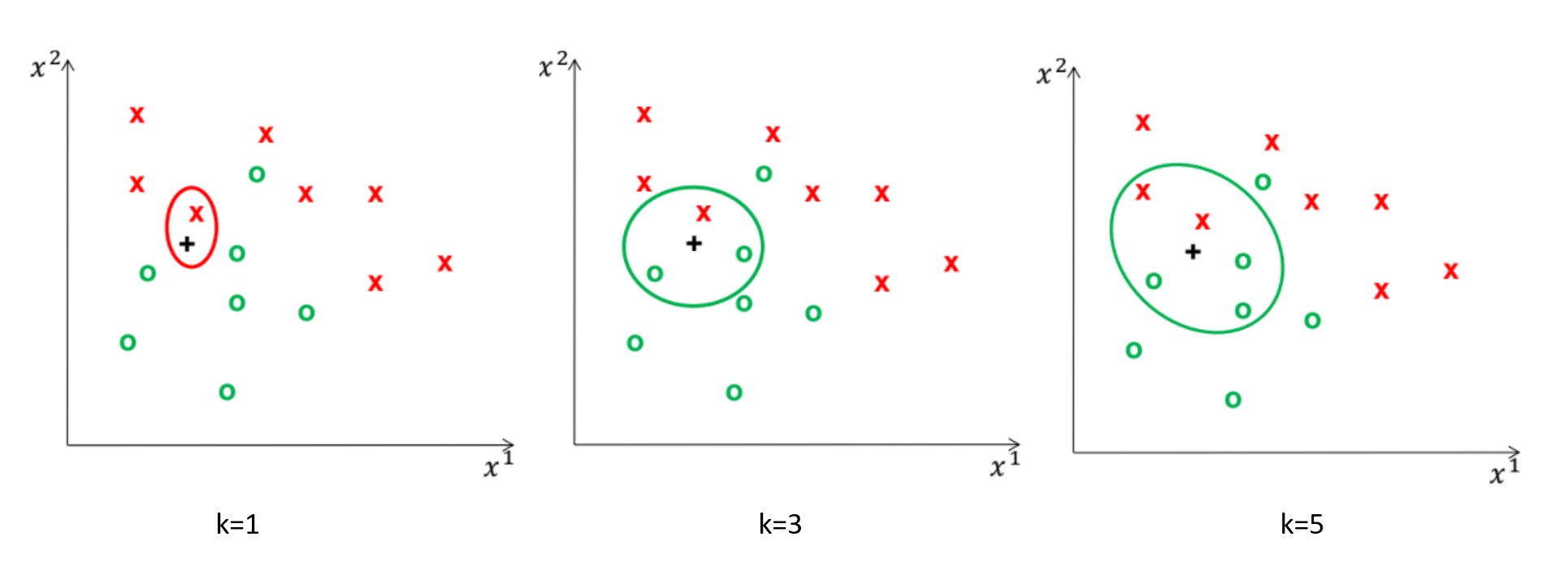
訓練階段:存取所有訓練資料$x_i$與其對應的類別結果$y_i$
測試階段:
距離量測方法:可使用歐式距離
參數$k$的不同會影響輸出結果
選擇參數k的方法:cross validate
把資料分成多個子資料,測試參數在小樣本中的表現結果
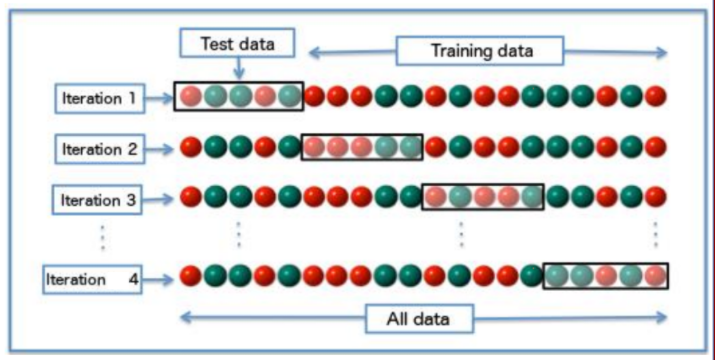
測試流程: