機器學習架構

- 分成training與Testing階段
- Training:準備訓練資料與對應的類別${(x_1,y_1),(x_2,y_2),…,(x_N,y_N)}$,評估預測函數$f$並最小化在訓練資料上的誤差
- Testing:輸入不在訓練資料內的未知資料,應用訓練好的fuction $f$來預測類別結果
K-nearest neighbor classifier
KNN的概念是由nearest neighbor algorithm衍伸出來,NN是透過一群已經存在的訓練資料與標籤當作基底,來對測試資料進行比對,輸出與訓練資料相似度高的類別當作結果
而KNN與NN不同的則是取出前K個相近的資料做參考,來決定最終輸出的類別結果
KNN演算法流程
訓練階段:存取所有訓練資料$x_i$與其對應的類別結果$y_i$
測試階段:
- 輸入$x$,計算與所有訓練資料點的距離
- 選擇前$k$個鄰近$x$的訓練資料
- 統計鄰近訓練資料最高的對應類別結果
距離量測方法:可使用歐式距離
KNN 細節整理
- 如何決定參數k
- 相似度比對
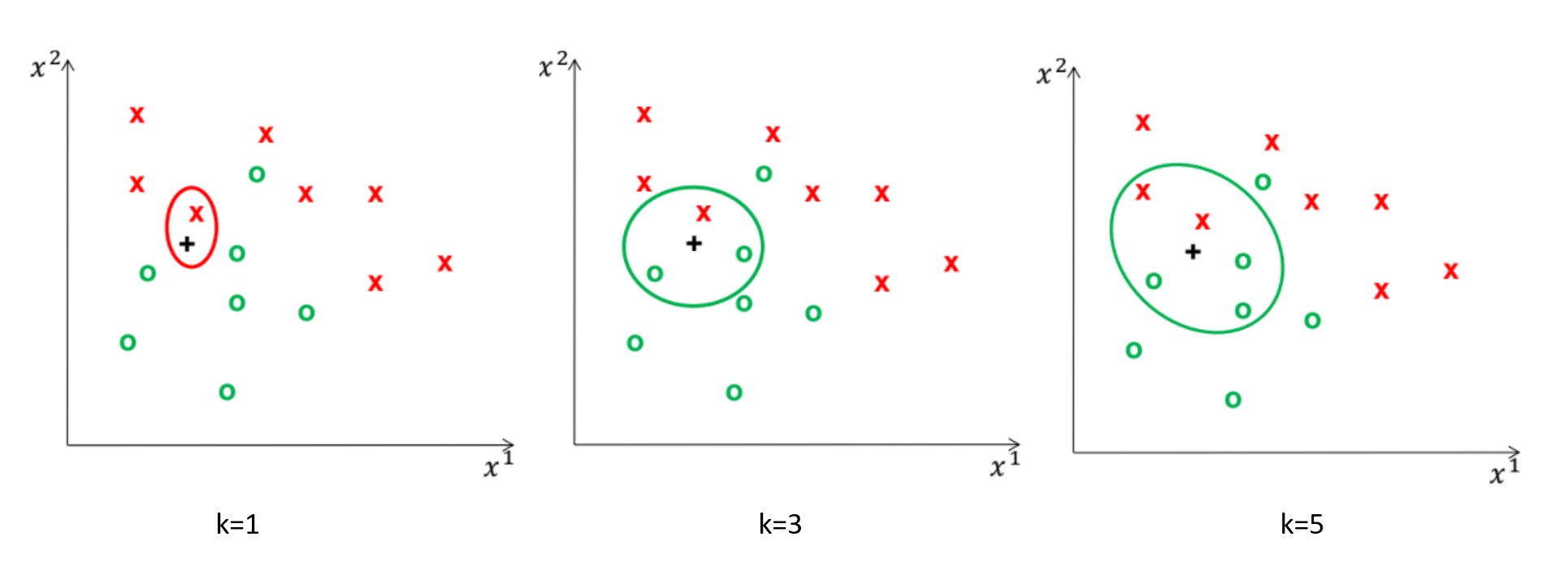
如何決定參數k
參數$k$的不同會影響輸出結果
- k太小,對雜訊敏感,容易overfitting
- k太大,容易underfitting
選擇參數k的方法:cross validate
cross validate
把資料分成多個子資料,測試參數在小樣本中的表現結果
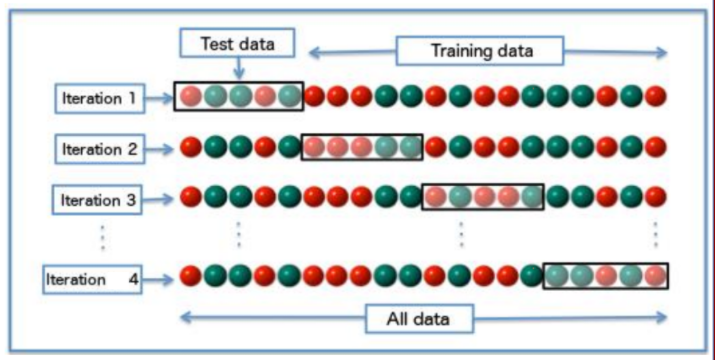
測試流程:
- 輸入訓練資料,從訓練資料分割成多組不同的訓練/測試資料
- 選擇在平均效能中最好的參數$k$
相似度比對
- 相似度比對:
- 相似度比對前都須對資料進行正規化,才能保證每個
維度的特徵具有相同的影響力,除了馬氏距離已將不同尺度的問題做處理