介紹
Visual bag of words視覺詞袋模型概念:將影像取出具有特徵的地方,存在待比對區域中,新影像進來時,逐一比對影像符合詞袋中哪個的特徵比較多,就跟詞袋中的影像越相似,常用來進行影像分類或影像檢索
新影像進來時,逐一比對影像符合詞袋中哪個的特徵比較多,就跟詞袋中的影像越相似,就可以將它分為詞袋中相近的那一類
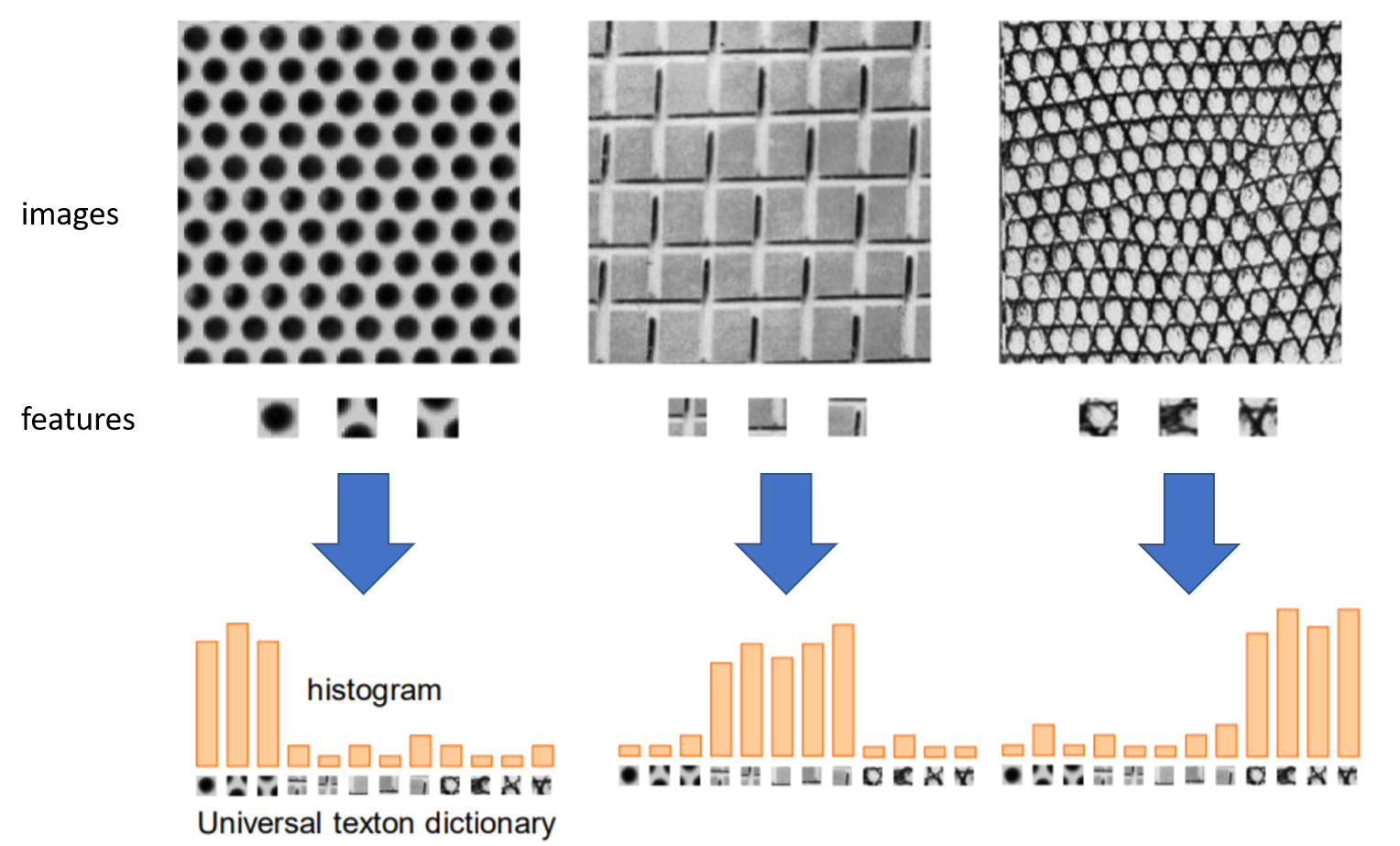 上圖可以看到在影像中,先取出各自的特徵,將這些特徵統一對各自影像進行評分,可以看到從原影像取出的特徵分數是比較高的
上圖可以看到在影像中,先取出各自的特徵,將這些特徵統一對各自影像進行評分,可以看到從原影像取出的特徵分數是比較高的
實作流程 & 方法
- 取出特徵
- 學習出專屬於每張影像的”視覺詞彙”,建立視覺字典
- 量化特徵
- 通過“視覺詞”的頻率表示圖像
特徵提取
特徵取得方式參考文本分析方法,文本分析中由單詞出現的頻率來去做分析,圖片則是由紋理特徵出現的頻率高低作分析
而課程中提到的方法的關鍵字:
- Regular grid
- Interest point detector
- Ramdom sampling 隨機採樣
- Segmentation-based patches
學習視覺詞彙
假設資料集中有狗、貓、飛機、山丘
透過剛剛的特徵提取可能會找到狗尾巴、貓耳朵、飛機的機翼、山丘上的樹等特徵
這些特徵之間會因為他們影像所呈現的方式而有相似性
我們在透過一個歸納個方法來將一群相似的特徵聚集再一起
使用k-means分群法來將相似的特徵組成一群
再取出各群之間的群心代表該群的特徵向量
- 問題:如何選擇視覺詞彙的大小
- 太小,此特徵向量不能表示所有群內的特徵性
- 太大,量化失真,overfitting
Vector quantization 向量量化
介紹codebook
codebook概念:codebook是由一群codevector或codeword組合而成,最終目標是以這些編碼向量來代表空間中全部的資料向量(ex:k means各群心的結果)
簡單來說,一組大資料用codebook內的codeword組合而成,用來降維,降低資料量
通過視覺詞彙的頻率來代表影像
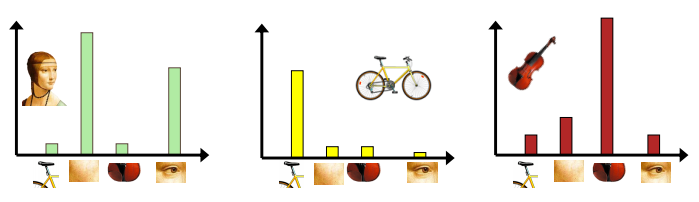
上圖可以看到當輸入的影像進來時,可以透過各個不同的特徵來評估他屬於哪一類,達到影像分類的效果
範例
作者使用11個類別,每類影像數不同
輸入影像後,取SIFT descriptor
再透過k-means分群法將特徵分成1000群
訓練一個SVM mdoel,輸入資料為k-means的群心與對應的類別標籤
輸入測試資料進行分類評估model準確度