論文連結:Fast Branch Convolutional Neural Network for Traffic Sign Recognition
簡介
論文使用深度學習架構來辨識交通號誌,辨識交通號誌是高級駕駛輔助系統的重要部分,像是方向號誌、限速號誌、各種警示號誌等等
論文遇到的挑戰是影像成像受到室外環境的複雜變化,如失真、惡劣天氣、過度曝光、曝光不足、運動模糊、褪色、複雜背景,造成辨識方法更具挑戰性
使用傳統的電腦視覺辨識方法在這多變的影像是很難以用單一個演算法流程得到穩健的辨識模型,因此使用CNN架構的模型來辨識
CNN往往需要大量的參數處理來得到結果,因此要達到即時辨識模型會有一定的難度,但目前也有許多即時的CNN模型,例如:YOLO
受生物機制的啟發,論文提出一個新的架構Branch Convolution Neural Network (BCNN),在神經系統中,簡單、反射動作會在神經系統較低層次做快速反應,困難的動作會在高階的神經系統處裡後做反應,例如:在容易區分的交通號誌圖片,人眼只看一部份也可以很快的辨識出來,套用在CNN上,沒有必要通過所有CNN參數才得到結果
CNN模型對資料的處理
CNN模型在輸入交通標誌資料有以下特性
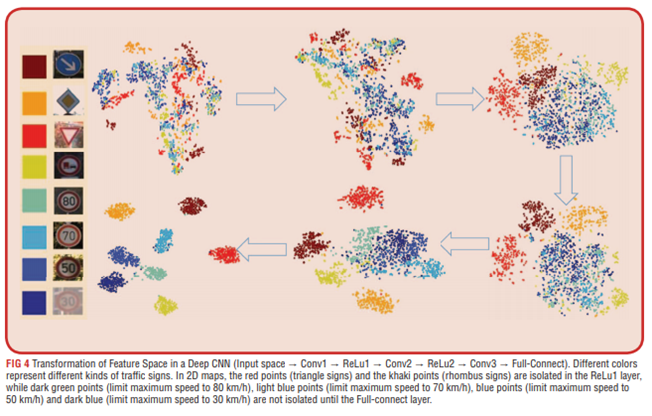
- CNN模型傾向於將原始混淆圖像空間轉換為線性可分離空間,並將同一類標籤的樣本聚集再一起
- 越難辨識到的交通標誌是與相同類別標籤樣本距離越遠的,表示模型辨識不到特徵
- 模型對形狀的辨識能力比辨識限速能力好,模型前期將三角形和菱形分隔開來,CNN模型參考圖形內標示較後期才分離不同數字
Branch Convolution Neural Network
CNN和BCNN的差別在於,BCNN會在層與層之間分支輸出結果,如圖所示,傳統的CNN模型會在最後Softmax層輸出結果,BCNN模型會在其中一個分支進行預測,因此可以提高模型的預測時間

所有的樣本都不需要經過整個CNN模型,參考前段介紹的生物學機制,簡單好辨識的影像在前期的layer預測,較難的影像在後期的layer輸出結果
BCNN model訓練流程:
- 訓練分支分類器
- 評估和偏移分類器
- 最佳化分支分類器
- fine-tune model
分支分類器 Branch Classifier
分支分類器是用來快速、高精度的輸出結果,因此false negatives是允許的,但false positives是不行的
因此簡單來說分支分類器:
- 簡單且快速
- robust與高精度
- 只輸出足夠置信度的樣本
由於分支分類器是使用線性分類器,使用k-folder來訓線性分類器,但分類器分的精度太高,也是沒有意義的,例如:分類結果為一個空間只有一個正樣本,他的precision是1,但recall可能非常低,因此設定precision與recall的threshold是必要的
再來就是要考慮到底要在哪幾層加入分類器,當遇到難以識別的樣本,並不會在分支分類器輸出結果,因此需要謹慎考慮分類器的插入位置與數量
迭帶搜索最佳組合流程
- 將分支分類器的組合編碼到[0,1]之間
- 設定$T_{save} $為目標函數
- 隨機產生不同種的分支分類器組合
- 計算$ T_{save} $
- 迭代到指定次數或找到$ T_{save} $符合閾值的組合
其中$ T_{save} $表示的是節省的時間,因此要最大化目標函數
$ T_{save} $公式:
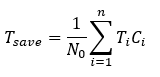
參數定義

$ l_i, i=0,1,2…n+1, 表示CNN第i層, l_{n+1}是輸出的layer, l_0是輸入的layer $
$ T_{l_i}是第l_i層到l_{n+1}層花費的時間 $
$ C_i 表示第i層的branch classifier是否存在,當C_i=1,存在分支分類器,C_i=0則不存在 $
$ t_i 是C_i分類器對sample處理所花費的時間 $
$ S_i 是到C_i層還沒被分類的sample $
$ C_iS_i第i層分離出來的sample數 $
$ S_i^*是第i層還沒被分離出來的sample $
$ N_i^* 是 S_i^* 的數量 $
$ N_0是所有sample$
$ N_i是到第i層的sample數量 $
$ N_i^- 是第i層還沒被分類出來的數量 $
$ T_i 是第i層的sample數量 - 第i層前節省的時間 - 未分類數量*分類器平均時間 $
$ T_{save}是平均節省的時間 $
測試
測試資料
- 從10小時的影片取出來的交通號誌benchmark,benchmark資料來源
- 共有43類的標誌
- 訓練資料:39k影像
- 測試資料:12k影像
- 15x15~222x193的影像大小
- 影像包含交通標誌本體再向外延伸 10%的長寬

測試結果
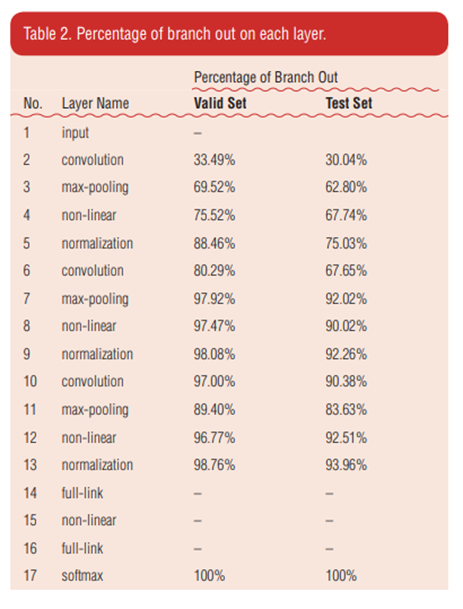
圖表顯示每個分支分類器分離輸入影像的百分比,將近30%輸入影像從第二層分離出來,並且將近75%從第五層分離出來。
這意味著可以提前分離出大量sample。 所以,BCNN可以節省大量無意義的計算。
儘管設置了一個高精度閾值,但不可避免地還是會有sample被錯誤分類。
就像訓練的準確性和測試準確性之間的關係一樣,原始模型和BCNN準確性之間存在較大差異。
圖片內的(a)顯示是在第5層之前隨機分離出的符號,(b)是在最後12層中隨機分離出的符號。(b)中的符號顯然更扭曲,模糊和更暗。與(a)相比,(b)中的樣本難以區分和識別。
我們將在前一層中分離出來的樣本命名為簡單樣本。更難識別的交通標誌被識別出來,後來被識別出來。
它與生物學機制一致,即簡單的動作被整合到一個較短的感知,而復雜的序列則以更長的周期被整合。
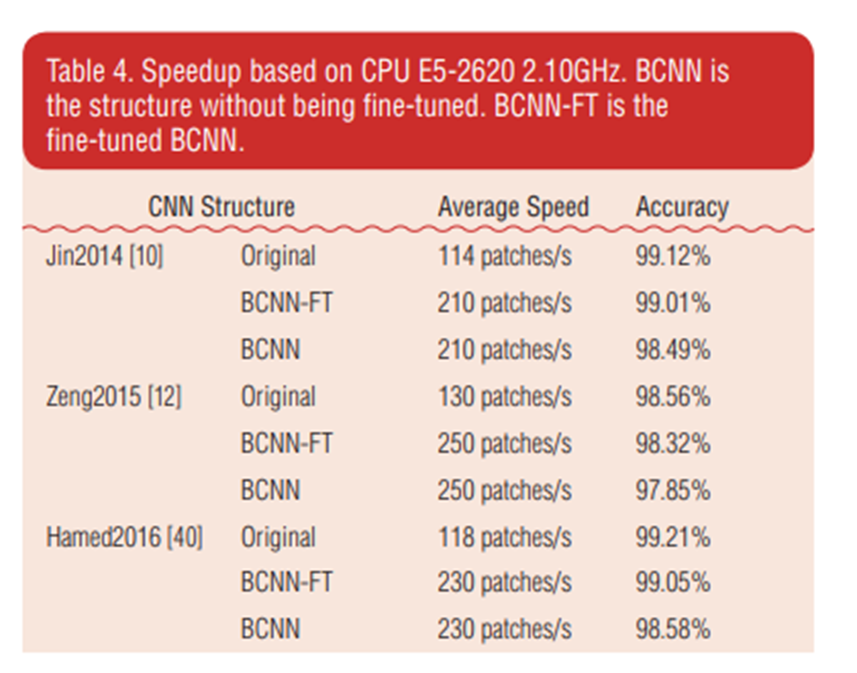
可以看到在準確度與原始CNN差異不大情況下,速度提升了約兩倍
在BCNN-FT,Fine tuned微調的情況下,更接近原始CNN的準確率
總結
- 受生物機制的啟發,提出了一種名為BCNN的交通標誌識別新框架
- 在相同的條件下比一般的deep CNN更快
- 在GTSRB的dataset下測試,大量的交通標誌可以在淺層分離出來