物件檢測是視覺中常見的任務之一,在影像中透過各種演算法來偵測到物件位置,常見的檢測如找到物件位置,並用矩形框標註,更精細一點的可以分割出物件的輪廓,其中會遇到的挑戰:
- 物件亮度不同
- 影像角度不同
- 物件的形狀變化
- 同類型不同型態的變化,例如顏色
因此為了測試演算法在不同類別上都能有強大的適應性,網路上有多種不同的大型影像資料庫,並附上物件的位置、類別資訊來進行驗證,以下介紹常見的影像資料庫PASCAL VOC、ImageNet、COCO
Benchmarks
PASCAL VOC Challenge
介紹
網頁上有每一年的資料更動,起初只有四個類別,1578張影像,比賽方式為檢測與分類
經過多年的資料量擴增,變為20個類別,含有11530張影像,並且有27450個ROI影像與6929個更精細的分割影像區域,並加入影像分割挑戰
競賽從2005年到2012年停止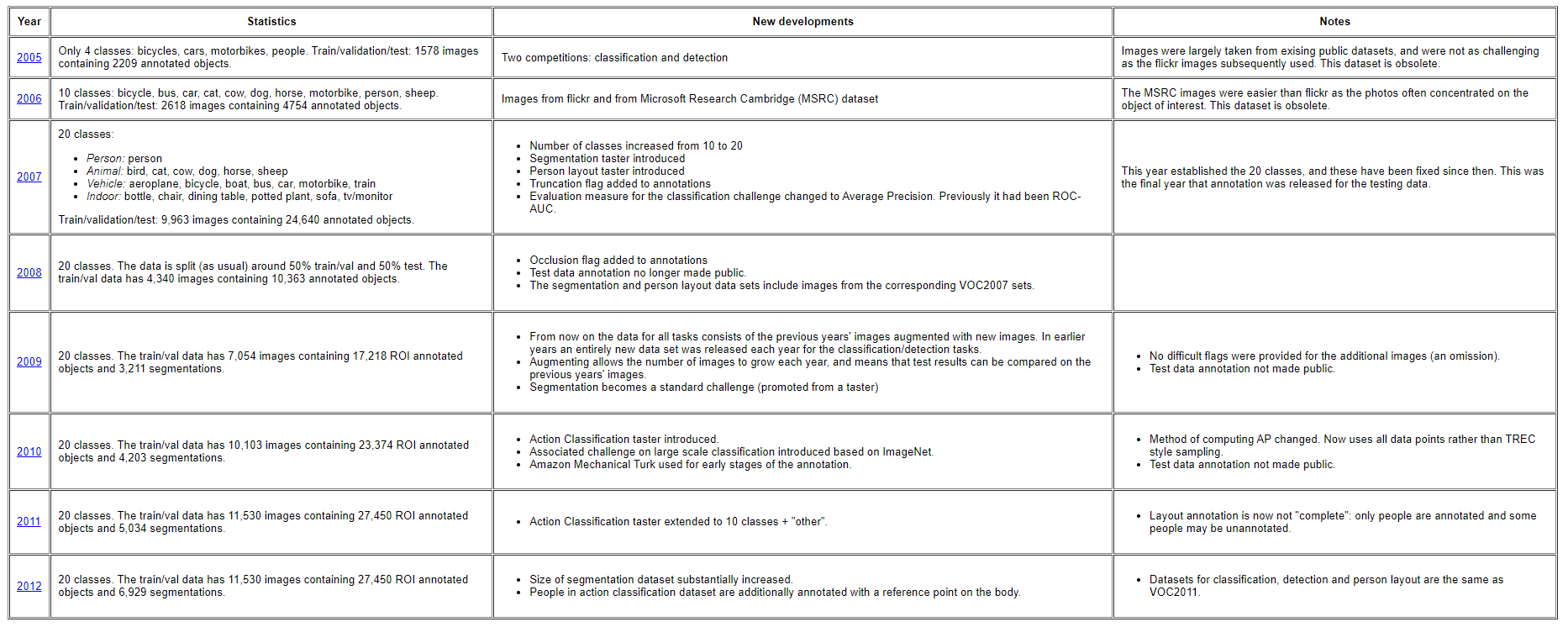
相關連結
PASCAL Visual Object Classes Homepage
paperswithcode PASCAL VOC Semantic Segmentation
ImageNet Large Scale Visual Recognition Challenge (ILSVR)
ILSVR介紹
ImageNet是一個提供所有研究人員進行大規模影像辨識模型的資料庫,資料庫內以手動標註了1400多萬張影像,並包含2萬多個類別,實際進行挑戰時會整理出1000類來進行比賽
其中ImageNet的標記類別是根據WordNet的結構,WordNet可以想成是一個辭典,這個辭典把相近意義的同義詞連結再一起,成為一個網路架構
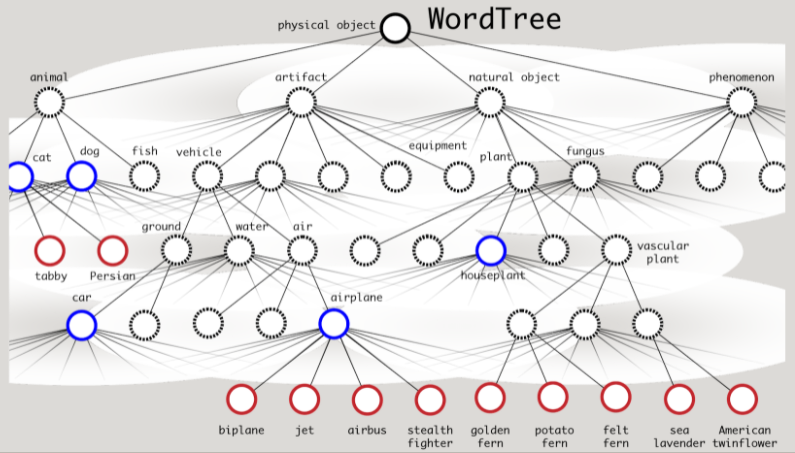 引用YOLO9000的圖來說明,WordNet結構是一個樹狀結構,一個節點下有多個子節點,例如飛機節點,下面有雙翼飛機、噴射機、空中巴士、隱形戰鬥機,因此在ImageNet中看到這些標記類別,都可以視為飛機類別
引用YOLO9000的圖來說明,WordNet結構是一個樹狀結構,一個節點下有多個子節點,例如飛機節點,下面有雙翼飛機、噴射機、空中巴士、隱形戰鬥機,因此在ImageNet中看到這些標記類別,都可以視為飛機類別
ILSVR相關連結
Download ImageNet Data on Kaggle

paperswithcode ImageNet object detection
的數據可以看到歷年來ImageNet影像分類比賽準確率的模型
Common Objects in Context (COCO)
COCO介紹
COCO dataset也是一個大型物件檢測、影像分割的一個資料集,他的特點參考官網介紹:
- 具有物件分割區塊
- 330K的影像數,有200K已經標記
- 包含1.5M個物件
- 物件類別有80類
- 場景分類有91類
- 每張圖片都有五個人工書寫的英文註釋
- 250000個person類別針對肢體做標記
COCO相關連結
paperswithcode coco object detection
評估模型方法
在物件檢測中,常使用precision, recall來評估模型
講到precision, recall前先介紹混淆矩陣與真陽TP、真陰TN、偽陽FP、偽陰FN
- 真陽(True Positive, TP):預測為真而實際為真
- 真陰(True Negative, TN):預測為假而實際為假
- 偽陽(Flase Positive, FP):預測為真而實際為假
- 偽陰(Flase Negative, FN):預測為假而實際為真
precision, recall公式:

precision公式意義:預測的為正樣本的結果中,預測正確的比率,稱為準確率
recll公式意義:取出所有正樣本結果,實際預測多少正樣本的比例,稱為召回率
以垃圾郵件分類器來舉例precision, recall數值高低的關係
垃圾郵件資料為正樣本, 不是垃圾郵件的資料為負樣本
分類器的precision高, recall高, 代表這模型非常棒, 具有濾除垃圾郵件的能力
precision高, recall低, 代表這模型預估是垃圾郵件的正確率很高, 但實際抓到垃圾郵件的數量少, 是謹慎的模型
precision低, recall高, 代表這模型垃圾郵件幾乎都有抓到, 但誤判率高, 是寬鬆的模型
precision低, recall低, 這模型沒用了
好的模型是具有高準確率,又有高召回率,因此可以使用我兩個都要的F-score指標
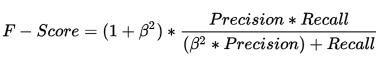
$\beta$ 值用來控制precision與recall之間的權重, $\beta$ 值越高,precision的結果就比較重要