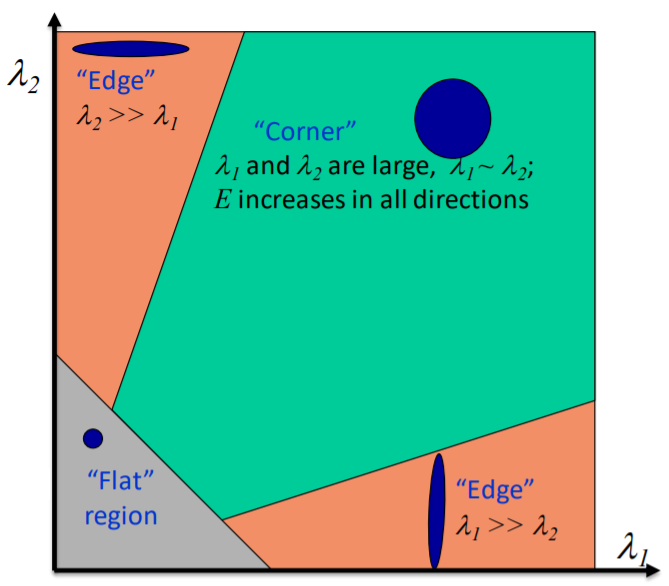
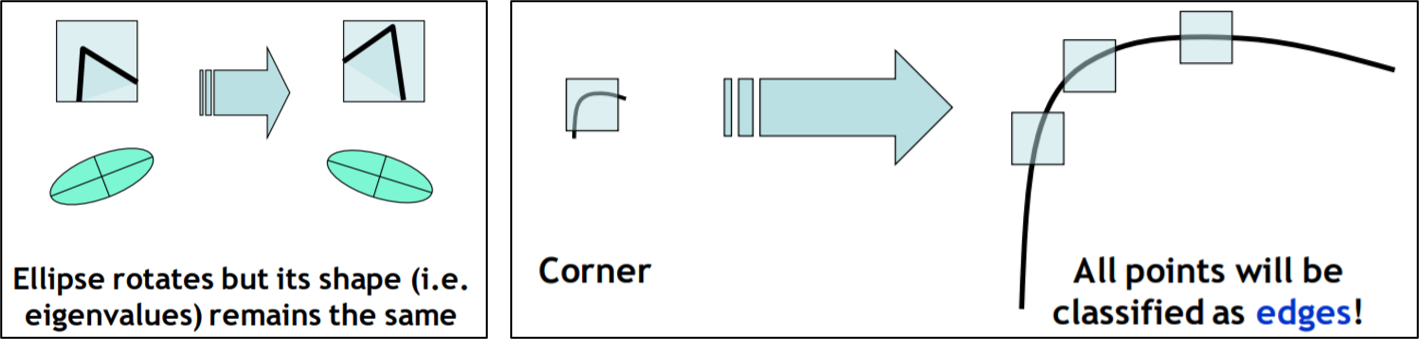
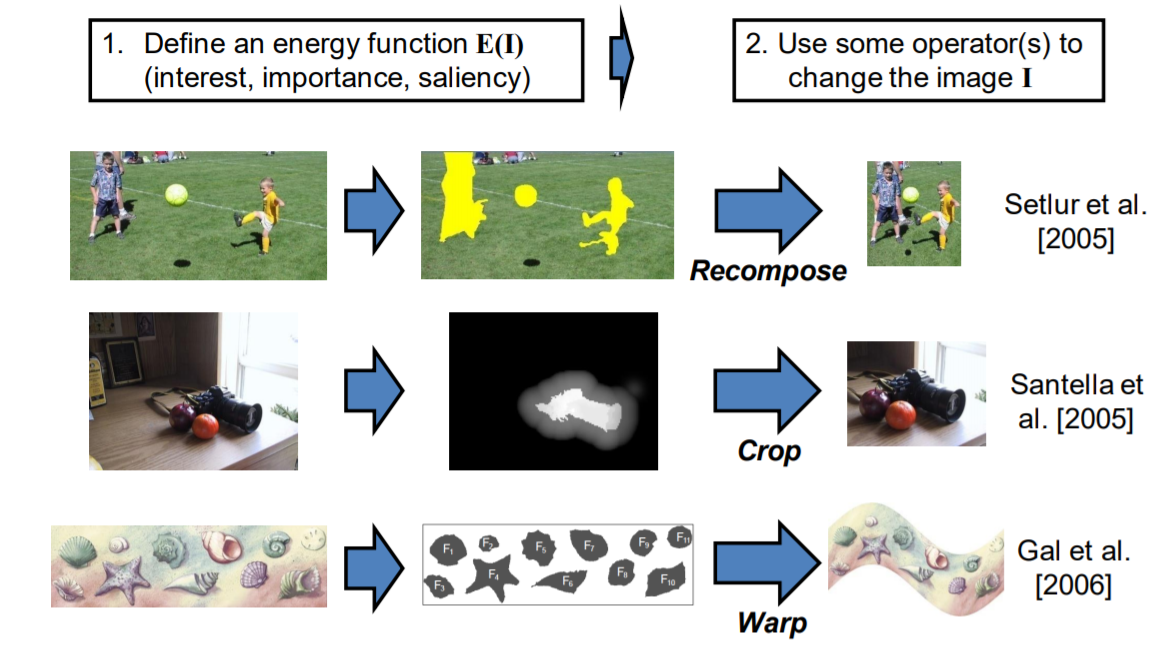
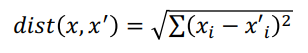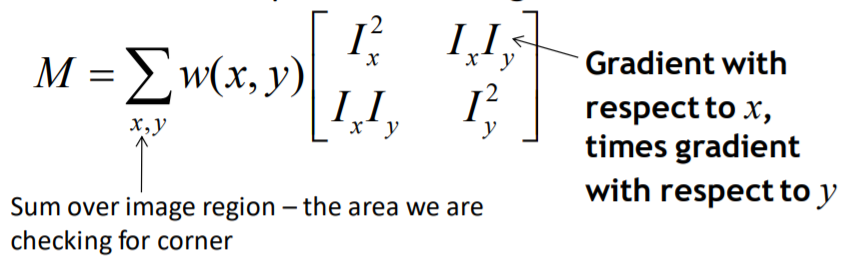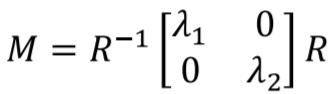如何保留重要的資訊又縮減尺寸,其中定義甚麼是重要,甚麼是不重要的影像資訊
Basie Idea
不重要的資訊代表影像梯度變化小的地方,定義一個energy function/
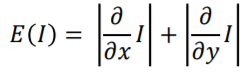
使用梯度來作為energy function的原因:
- 邊界代表紋理資訊
- 人眼對edge比較敏感,平滑處就可以被視為不重要資訊
- 概念很簡單
左圖對整張影像濾除低能量pixel
中間對每行方向濾除最低能量pixel
右圖對每列方向濾除最低能量pixel,看起來結果較好一點,但仍看得出來階梯處有扭曲的感覺
Seam Carving
接縫裁剪(Seam Carving),是一個可以針對圖像內容做正確縮放的算法。概念上,算法會找出一系列的接縫(seam)(接縫是在圖像中最不重要的一連串像素),接著利用接縫對圖像做縮放。如果是要縮小圖像,則移除這些接縫,若是放大,則在這些接縫的位置上,插入一些像素。接縫裁剪可以人工定義一些不會被修改的像素區域,也可以從圖像中移除整個物體。by wiki
流程
- 輸入要變化的影像與尺寸
- 計算energy function
- 從energy function計算seam cost $M$
- 選出裁切方向最小的seam carving
- 濾除足夠多的行列直到與輸入尺寸相同
計算Seam cost的部分,主要使用動態規劃的方法來實作,因為每次計算seam cost時必須計算與鄰居周圍的相關資訊
重新定義參數:
- $E$是前面提到的energy function,$E(i,j)是在影像上對應i,j的座標點能量值$
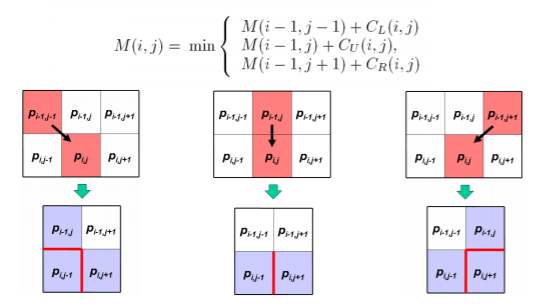
- $M$是seam cost,用來評估將該點作為seam carving時依據,$M$的計算公式:
$M(i,j) = E(i,j) + min(M(i-1, j-1), M(i-1,j), M(i-1, j+1))$
- 可以從公式看到,seam cost所代表的意義就是由該點所對應的energy function,加上鄰近上方像素的最小點,就可以當作今天要把該點去除或展開時的一個成本,成本高低代表該點是重要資訊的指標

Dynamic Programming
由於seam cost公式是計算矩陣$M$,其中又參考到自身周圍計算過的數值,因此需要用到動態規劃(Dynamic Programming, DP)
$M(i,j) = E(i,j) + min(M(i-1, j-1), M(i-1,j), M(i-1, j+1))$
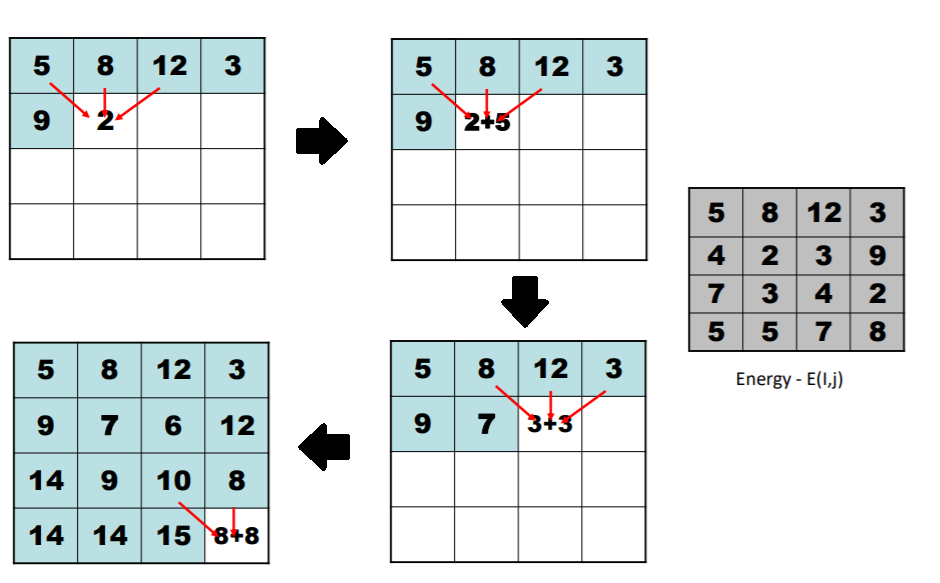
Searching for Minimum
得到seam cost矩陣後,從最下方開始尋找最小向上路徑
搜尋方式是先選出下方最小起始點,向上沿著上方周圍三個鄰居來選擇最小數值,直到矩陣上方列
結果

一隻胖鳥經過Scaling瘦身成功,Retarget才能呈現他的身材!
Extensions
Imporve the running time
在流程中,我們只需更新被濾除掉的seam carving像素點集合周圍的energy funciton,而不必更新整張影像的energy function
Retargeting in Both Dimensions
在流程中,如果都需要調整寬高,那應該先調整哪個方向
或著是透過一個方法同時調整寬高
同時重新調整寬高的思路,同時考慮到x,y方向的seam cost
並將他合成一個選擇公式:
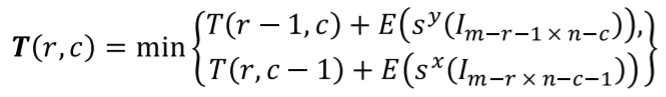
$c,r$ 是行與列,考慮到x,y方向的seam cost,個別移除水平與垂直方向的結果
找出最小化的seam
Multi-Size Image Representation
上述流程是在知道輸入調整尺寸的情況下做演算
那假如在不確定輸入尺寸的情況下(ex:顯示的尺寸可能有各種不同的組合)
要如何做到即時resizing的轉換
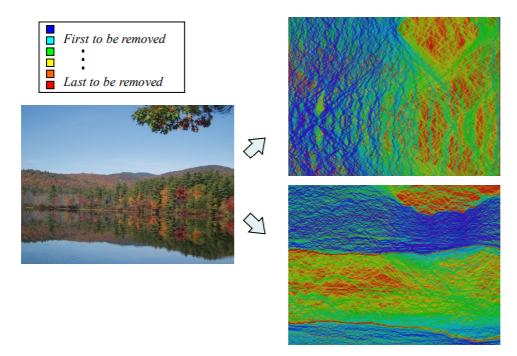
那就先把整張影像上x,y索引的seam 的計算完排序並存起來,當今天要縮剪k個長度,就刪去前k個seam
Object Removal
設定mask來保護/移除指定的區塊

Limitations
seam carving的侷限性,低能量區域
- 低能量區域的移除造成影像細節的幾何變化
- 低能量區域在某些情形下也可能是重要資訊,ex:人臉

改善方法:
使用自訂義限制,ex:人臉因為低能量區域被移除造成人臉扭曲,那就用人臉檢測保護臉部區塊+seam carving

Improvement: forward energy
seam carving導致平均能量不停上升,並且會有鋸齒狀的邊緣
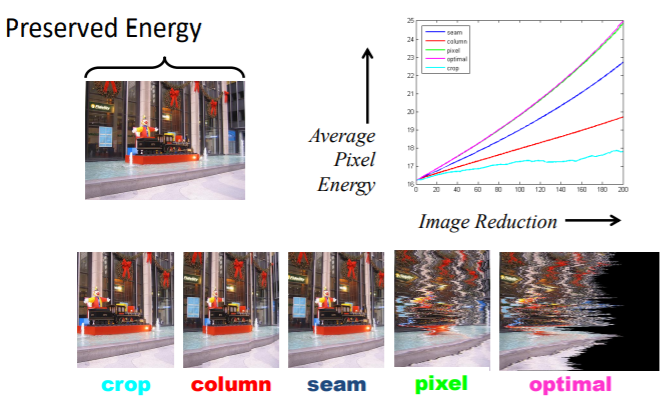 改變移除策略:
不移除最小能量的seam,而是移除插入能量最小的seam
改變移除策略:
不移除最小能量的seam,而是移除插入能量最小的seam

$C_L$是計算移除$𝑝_{𝑖,𝑗}$後左右,上下的能量,以此類推
得到每個移除接縫後的能量總和,用來評估哪個方向的像素被移除可以得到較小的能量
小能量代表移除後得到平滑影像,大能量代表出現梯度變化大(扭曲、鋸齒狀)的結果
比較forward & backward結果


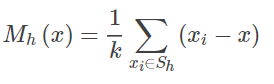
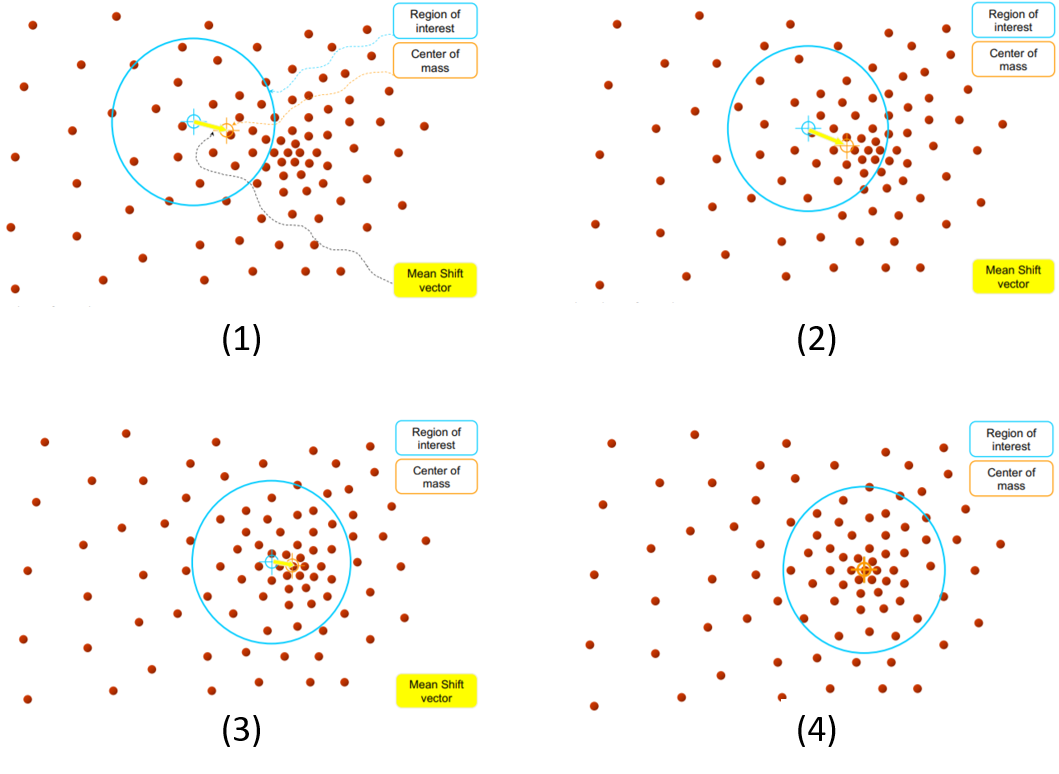
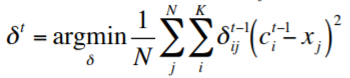
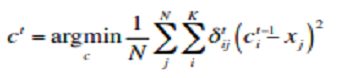
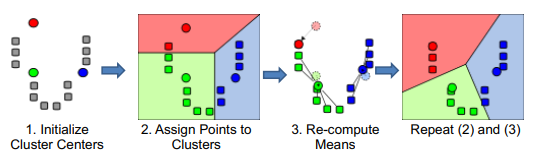

 * 需要決定參數k
* 需要決定參數k


{: width="881" height="342")