論文名稱:Mean Shift, Mode Seeking, and Clustering
流程:
- 隨機初始化起點與視窗$h$
- 計算中心重心
- 移動搜索視窗到重心位置
- 重複步驟2~3直到收斂
重心計算公式:
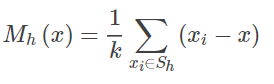
其中$x是輸入的資料集,x={x_1,x_2…x_k},x_i是第i個資料$
$S_h是視窗半徑為h$的區域
mean shift 演算法範例: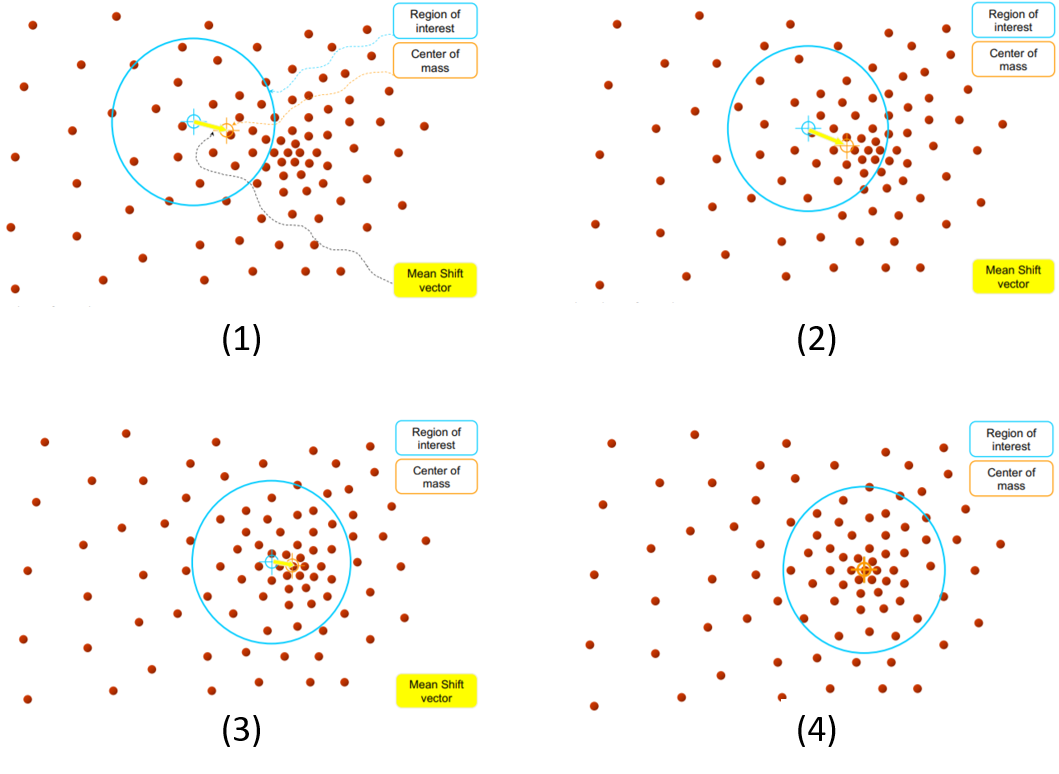
圖(1)~(3)計算重心並移動,移動幅度(1)>(2)>(3),圖(4)收斂
特性
- Unsupervised learning
- 跟k-means不同的是,不用先假設資料有幾群
- 調整一個視窗大小參數,並且具有物理意義,視窗大小代表中心的搜索範圍,但視窗範圍會影響到輸出結果
- 對outliers具有穩健性
- 資料維度越高,運算越巨大