論文閱讀:Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories
作者Svetlana Lazebnik, Cordelia Schmid, Jean Ponce
Abstract
本論文提出一個方法來進行場景辨識
將影像劃分成越來越細的子區域
並計算每個子區域內的局部特徵直方圖
Feature extration
可以分成兩種特徵
- weak features
- oriented edge points
- visual vocabulary較少
- strong features
- SIFT
- visual vocabulary較多

Spatial Pyramid Matching
Create Pyramid Histogram
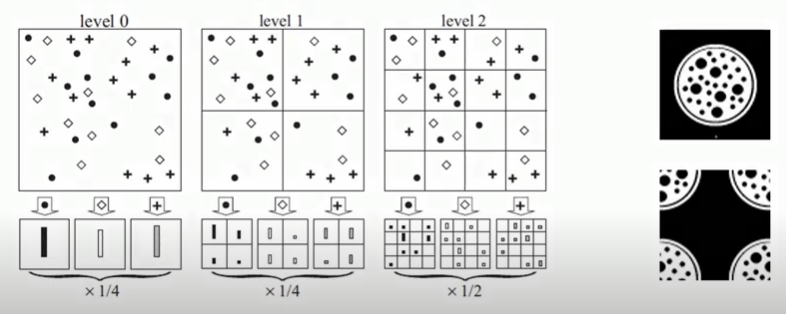
右上圓圓像細胞的是輸入的影像
左邊三個level是本篇文章提出的一個分割方法
隨著level提高, 分割的數量逐漸增加, 概念就跟金字塔一樣
從level 0來看,將輸入的影像經過特徵萃取
每個點代表不同的Bag Of Visual Words
計算每個特徵個別總和並用直方圖表示,如level 0下的長條形

而在level 0最終可以得到一個1*3的向量來表達這張影像
到level 1部分,將影像切成4等份
因此下面的直方圖也會有四份
順序是對應著圖中的紅色數字進行量化
level 1就可以得到1*12的向量
level 2就可以得到1*48
再拿這些向量去對其他影像進行比對
Pyramid Matching
在原論文3.1節寫到如何匹配
定義X,Y是兩個取出d維特徵向量的集合
$ \ell $ 是金字塔的等級,第l等級會有 $ 2^{\ell} $ 的網格數
每個網格會有$D= 2^{\ell d} $的維度向量
定義 $ H^{\ell}_X $, $ H^{\ell}_Y $ 是X,Y對應的histogram
匹配公式:

用下面的例子來簡單舉例:

可以看到在level 0 兩邊都至有8個點
level 1 左上最少 1, 右上最少 1, 左下最少 2, 右下最少 2 點以此類推
其實公式的精神就是再說,取出X,Y每個格子的的最小數量作為交集數量
而level與交集數量的關係:
level 0 是一個全局的角度,因此早期的匹配到很多點數量不代表真的相似,因為level 0並沒有任何空間的訊息,隨著level越來越高,分割越細,所match到的點數量越能表示他們的相似程度
因此每層的權重公式:
level0 權重 = $ \frac{1}{2^L} $
其他 = $ \frac{1}{2^{L-\ell+1}} $
由於金字塔的計算方式,會有點數重複計算到的問題,為了消去這個重複性
計算第 0 層到第 $ L-1 $ 的實際點數公式為:
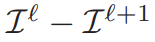
把上述兩個公式合在一起得到pyramid match kernel:

論文將所有特徵向量量化成M個離散形式,最終公式為:
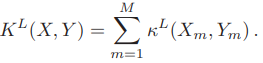
使用SVM訓練模型來進行多個類別分類
Sample Code
Spatial Pyramid Matching Scene Recognition
參考
Spatial Pyramid Matching presented by Lubomir Bourdev
C 7.2 | Spatial Pyramid Matching | SPM | CNN | Object Detection | Machine learning | EvODN